
For 30 years, we’ve built software that tells users how to work. The next generation will watch users work and become the tool they need.
We’ve Been Guessing for 30 Years
Every piece of enterprise software you've ever used was built on the same assumption: we know how you work. A product team imagines a workflow, encodes their opinions into a UI, and ships it. The user adapts. If they're lucky, the team got it 70% right. The other 30% becomes workarounds, feature requests, and Jira tickets filed into the void.
That model made sense when software was static and intelligence was expensive. Neither of those things is true anymore.
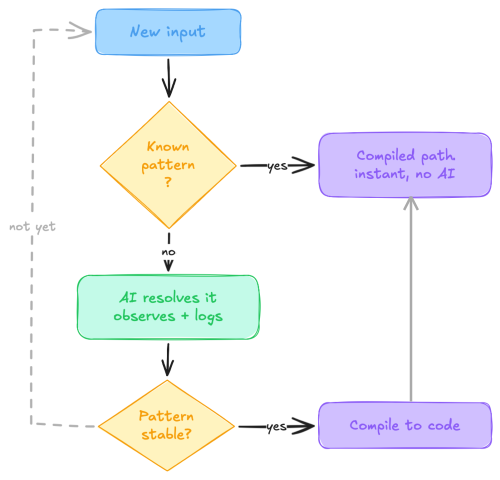
Adaptive Software is what happens when you flip the arrow. Instead of prescribing workflows, the system observes real usage and shapes itself around it. Repeated behavior stops generating analytics dashboards nobody reads and starts generating new capabilities. The system takes a messy input it's never seen, figures it out with AI, and then, after seeing that pattern enough times, writes its own deterministic code path so it never needs AI for that task again.
No Jira tickets. No "let's revisit in H2." The software evolves because people used it.
How It Gets Smarter
Adaptive Software rests on two ideas that work together. The first makes the system smarter. The second makes it faster. Together, they shift expensive AI inference toward cheap, deterministic code… while expanding what the system can handle.
Part 1: Adaptive Memory
The system accumulates context so it makes better decisions with each interaction.
I’ve been living in this pattern for months through the process I described in The Model Monsoon. Each agentic coding cycle writes its learnings to persistent files (gotchas.md, patterns.md, session-handoff documents). These capture what worked, what broke, what we corrected. A fresh agent session with a clean context picks it up and knows what to do. Nobody re-explains the history. (This is Karpathy's context engineering: designing what your agent knows before it starts thinking.)
Before Adaptive Memory, agent sessions were like the blindfolded relay challenge in Top Chef Season 6; each agent picked up the dish cold, reading whatever clues the last one left behind. Adaptive Memory takes the blindfolds off. Every session inherits the full resolution history, so handoffs are seamless and nothing gets re-explained.
When the system encounters something new, it doesn’t fail or hallucinate a guess. It interviews. An LLM-powered triage step asks targeted clarifying questions, captures the Q&A, and logs the full resolution path. Every ambiguous interaction becomes a stored lesson that prevents the same ambiguity next time. The memory layer grows organically; nobody maintains it.
Part 2: Adaptive Action
Here's where it gets weird... but in a good way.
The system doesn’t get smarter by remembering alone. It writes code for itself.
When the observation loop detects that the same pattern has been resolved by AI multiple times… zero remaining ambiguity… it promotes that pattern from “AI-mediated” to “compiled.” A deterministic code path gets generated (a parser, a mapper, a rule). Subsequently, that specific case runs without any AI inference at all. The system upgraded its own capabilities. Nobody specced it. Nobody designed it. Nobody coded it. It grew.
Think of it like a JIT compiler. First time a function runs, it’s interpreted; flexible but slow. When the runtime notices a hot path executing the same way on repeat, it compiles that path to optimized machine code. Same logic, much faster execution. In Adaptive Software, the “source code” is user behavior and the “compiled output” is a new deterministic function. The system watched you work and built itself a shortcut.
I Tried This in 2019 (Before the AI Was Ready)
In 2019, I worked on a product called Kormo at Google. It was a jobs platform for entry-level workers in emerging markets, starting in Bangladesh. During research we noticed something: new grad job seekers almost universally had paper CVs. Photocopied, hand-formatted, carried around in folders. Our onboarding flow asked them to re-enter all that information into a structured form… name, education, work history, skills. It was tedious and it was the biggest drop-off point in the funnel.
So we built something that felt cutting-edge at the time. Point your phone camera at your paper CV; the system runs OCR, parses the text, and pre-fills the form fields. Take a picture and voila… your resume is imported.
It was a b*&ch to build. And it never fully worked. Sure, it was better than manual entry, but users still had to clean up misplaced fields, fix garbled text, and re-enter anything the system missed.
The problem was variability. CVs in Bangladesh don’t follow a standard template. Some have education at the top; some bury it in the middle. Some list skills in a table; some in a paragraph. You get the idea. We spent months tuning parsers and heuristics, and the result was… okay. We shipped a prescriptive parser that assumed a structure, and real-world documents didn’t cooperate.
Now Imagine It Adaptive
Day one, the system ships with no CV templates and no field-mapping rules. A user photographs their paper CV. An AI agent reads it, identifies candidate fields (name, school, graduation year, work history), maps them to the profile schema, and asks one or two clarifying questions. “Is ‘Dhaka College’ your most recent institution?” “Is this a graduation date or an enrollment date?” It logs the full resolution path.
The user corrects a couple of fields. Those corrections go to the memory layer. Next CV that looks structurally similar? Fewer questions, better field placement. The AI is still doing the parsing, but it’s getting more accurate with each interaction.
By the Nth CV in a recognizable format (say, the photocopied template that half the career centers in Dhaka hand out), the observation loop flags it. “Resolved. Zero ambiguity.” The system generates a deterministic parser for that specific layout. Next CV in that format? Parsed instantly. Zero AI. Zero cost.
A completely different CV format shows up… typed, landscape orientation, skills in a sidebar. The AI handles it, learns it, compiles it when it’s seen enough. The system grows a library of compiled parsers, each one born from real usage in a specific market. No product team had to anticipate the format. No engineer had to hand-code the mapping.
But here's what gets interesting. The system has now parsed thousands of CVs. It knows what's on them (e.g. skills, education, location, work history). And it notices something no product team anticipated: the data it just ingested is exactly what employers use to screen candidates. Nobody built a pre-qualification feature. Nobody specced a "match score" module. But the system has all the inputs on one side and all the job requirements on the other, and the pattern is obvious.
So it spawns one. A new capability where applications arrive pre-qualified, candidates matched to roles before they even start browsing, which was born entirely from the data the CV parser already captured. The product team was focused on intake. The system saw what came after.
We couldn’t build this in 2019. The AI wasn’t there. But the problem we were solving (and partially failing to solve) is exactly the kind of problem Adaptive Software is designed for.
Teach, Compile, Spawn
The lifecycle of any capability in an Adaptive system follows a predictable arc:
Unknown → AI-Mediated → Observed → Compiled → Spawned
New inputs start in the unknown zone (expensive, flexible). As patterns stabilize, they compile into deterministic paths (cheap, fast). When they stop firing, they get pruned. The system is always evolving; growing where there’s real demand, shrinking where there isn’t.
Three evolutionary moves drive this:
TEACH. The pattern involves ambiguity or human context. The system adds a lesson to the persistent memory layer. AI still handles it, but with better context next time.
COMPILE. The pattern is clear, unambiguous, and repeated. The system generates deterministic code. AI leaves the loop for that path.
SPAWN. Usage reveals a workflow the system doesn’t have a module for, so it creates one. A new specialist capability born from demand… not from a product roadmap committee that meets on Thursdays.
Ship the Kernel
For two decades, the industry mantra was “config over code.” Give users admin panels, template builders, field mappers. Let them configure their way to the workflow they need without touching a line of code. The entire SaaS model was built on this premise.
Adaptive Software inverts it. The system writes code (deterministic parsers, compiled paths, generated rules) so users never have to touch config. Config is the user doing the work. Code is the system doing the work. And it changes how we should think about three things.
We can ship earlier. If the system learns edges from real traffic, the first version doesn’t need to handle every permutation. Ship the kernel. Let usage teach it. The pressure to “cover every case before launch” is Storm Thinking; fear dressed up as thoroughness.
We can stop hand-coding bespoke parsers. We’re spending engineering cycles building mappings that an Adaptive system could learn and compile from actual usage. Often with higher accuracy, because the compiled paths reflect what users send rather than what we predict they’ll send. (Our predictions, in my experience, are about 70% right. Usage data is 100% right.)
We should be interrogating our own stack. Where are we running expensive AI work on repeat that could compile down? Where are we building rigid workflows that should start adaptive and crystallize over time? Where are we prescribing when we should be observing?
The era of prescriptive software is ending. The teams that figure out adaptive architectures first will ship faster, learn faster, and build systems that get better without anyone touching the code. Everyone else will keep building config screens.




